Tasks
Analyze Document
Extracts and classifies information from documents using OCR, entity extraction, ID proofing, and AI analysis. Useful for document intake, verification, and structured data capture.
Use Cases
- Use this task to extract text from a document
- Use to extract a data structure of all entities in a filled in form
- Use to extract data from a South African ID document
- Use to classify a proof of payment document as belonging to a specific bank in South Africa
If you are specifically wanted to extract financial information from an invoice or receipt, you should use the Analyze Financial File task.
Basic usage
Parameters
document_processor_type required string
The type of analysis that you would like to perform on the file.
Current Options are:
ocr
Extract text from a document with optical character recognition. The document can be a pdf or an image.entity_extraction
Extract entities and form fields from a document. The document can be a pdf or an image.id_proofing
Id proof a document, getting verification signals on image manipulation, verification of an id document and checking for suspicious words. The document can be a pdf or an image.classifier
Classify a proof of payment document as belonging to a specific bank in South Africa. The document can be a pdf or an image.parse_contents
Parse the contents of a document. The document can be a pdf, pptx, docx, html, xml.
[document_processor_type] required object
This object key must correspond with the document_processor_type.
This object will contain all the options and params for the selected document_processor_type.
For example, if the document_processor_type is ocr, then there must be an ocr object with the required options for the ocr processor type.
Show child attributes
params
This object contains all the options and params for the selected document_processor_type.
files
An array of file objects. Each object contains file meta data.
The most important key for these objects is the fileuuid
Show child attributes
fileuuid required string
The unique identifier of the file that should be transcribed.
Result
Properties
payload
The returned payload
total_pages
Number of pages analyzed
ocr
Contains all the analysis data for the ocr document_processor_type. This object with change to correspond to the document_processor type.
ocr.full_text
Contains all the text the analysis could get from the file
ocr.detected_languages
An array of objects. Each object in the array is a page of the file and indicates which languages were detected on that page of the document.
ocr.all_languages
An array containing language codes for all languages detected in the document.
OCR
Shown in the Basic Usage
Entity Extraction
This document_processor_type processor type is used to extract entity and form fields from a document.
Example would be a document that has an organization and fields that have information in them like a receipt, invoice, application form, etc.
It will attempt to identify the field name and the value of that field and create a key value pair. It will do this for each form field that it detects.
Here is an example of a form. Its a Fax Cover Sheet with a form with fields and entries for each field.
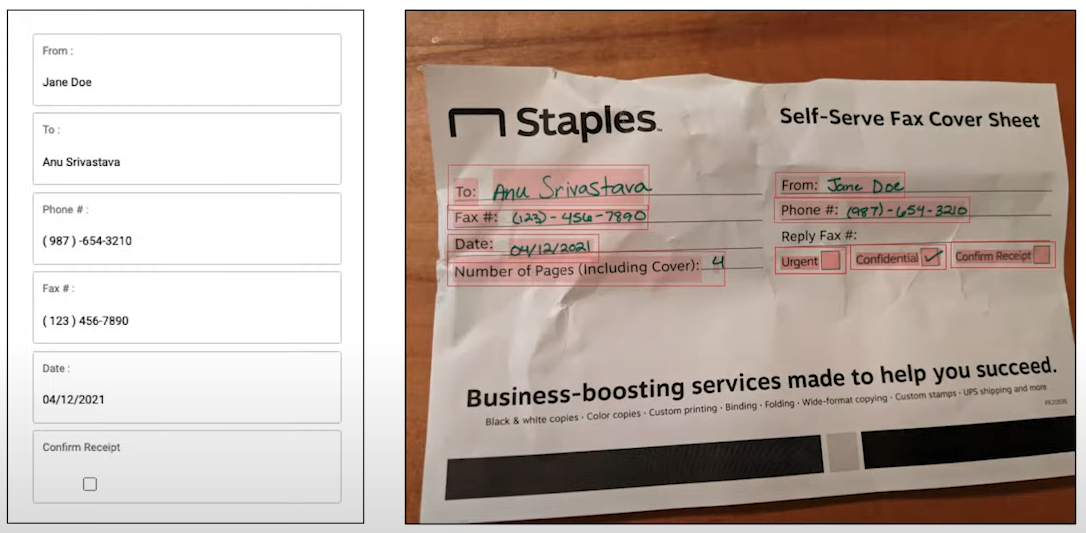
On the left is what it has extracted from the image displayed on the right.
You will notice the document_processor_type is now entity_extraction and so there should be the corresponding object with the same name referring to the file it should analyze.
Result
The result returned would look something like this. The returned data is quite large so only showing a sample of the important data that is returned.
The result payload is similar to the first example with a few additions:
entity_extraction
Contains all the analysis data for the ocr document_processor_type. This object with change to correspond to the document_processor type.
Please see above OCR example for explanations for the detected_languages and full_text objects & key values.
entity_extraction.entities
Contains an object for each entity detected. eg. organization is: Staples
entity_extraction.form_fields.pages
Contains an object for each page.
Each page is an object in the array and each page object contains an object for each field detected. eg. Date: 04/12/2021 From: Jane Doe
ID Proofing
This is used to extract all the information from South African Identity documents, ie. Green bar code ID Book, Smart ID Card or Passports.
It doesn't only extract the information, it also does fraud checks to indicate if the document is valid or fraudulent.
You will notice the document_processor_type is now id_proofing and so there should be the corresponding object with the same name referring to the file it should analyze.
Result
The result returned would look something like this. The returned data is quite large so only showing a sample of the important data that is returned.
The result payload is similar to the first example with a few additions:
id_proofing
Contains all the analysis data for the id_proofing document_processor_type. This object with change to correspond to the document_processor type.
Please see above OCR example for explanations for the detected_languages and full_text objects & key values.
id_proofing.id_proofing_signals
Contains an entry for each id proofing check performed and its result. eg. fraud_signals_suspicious_words: PASS
This indicates the suspicious words check passed inspection. No suspicious words found.
id_proofing.all_signals_passed
Indicates if all the id proofing checks passed. If one check fails, this will be false.
Parse Contents
This document_processor_type is used to parse the text from a document. The document can be a pdf, pptx, docx, html, xml.
It uses a Large Language Model (LLM) to parse the text from the document.
Parameters
These parameters are specific to the parse_contents processor type.
parse_contents.sites
An array of site objects. Each object contains site meta data.
The most important key for these objects is the url.
Only sites or files can be used, not both.
Show child attributes
url required string
The URL of the site that should be parsed. Will only parse this specific page.
parse_contents.params
The type of analysis that you would like to perform on the file.
Show child attributes
parse_mode
The mode of parsing to use.
One of fast, accurate, premium
Default: accurate
fast | Best for text-only PDFs.
accurate | Performs OCR, image extraction, and table/heading identification. Ideal for complex documents with images.
premium | Same features as accurate, and outputs equations in LaTeX format. Outputs diagrams in Mermaid format.
result_type
The type of result to return.
One of text, markdown, json.
Default: markdown
markdown and json are only available in accurate and premium mode.
parsing_instruction
The prompt to provide to the LLM to help it understand the context of the document. Applied to each page of the parsed document.
disable_ocr
Skip the OCR step. Useful for text-only PDFs as it will speed up the parsing process.
skip_diagonal_text
Skip any text that is not horizontal or vertical.
do_not_unroll_columns
By default multiple columns of text are parsed as a single continuous block. Set this to true to keep the columns separate.
Result
The result returned would look something like this. The returned data is quite large so only showing a sample of the important data that is returned.
full_text
Contains all the parsed text from the document. Typically in the format specified by result_type.